All Slides
CSC-430
Phillip Wright
About the Course
Overview
The high level goal of this course is to learn how to transition from coding for courses to coding in the real world.
The Plan
- Object Oriented Programming (review)
- Advanced Java
- Tools of professional development
- Design patterns
- Clean coding practices
- Software development processes
- …and more?
What do I know about the real world?
A lot! Teaching is my hobby; writing code is what I actually do for a living. I am teaching you the things I wish I had known when I graduated.
What people say about CSC-430
“Candidates used to struggle to get through the technical portion of interviews…now the technical questions are largely useless, because students do so well now…”
What people say about CSC-430
“…we started probing the students to find out what had changed and the answer was CSC-430”
A local employer (paraphrased)
Grading
| Component | Weight |
|---|---|
| Assignments | 68% |
| Exams | 28% |
| Misc | 4% |
Textbooks
For this course, we will be using the following textbooks, in addition to free online resources:
- Head First Design Patterns, 2nd Edition, Freeman & Robinson
- Effective Java, 3rd Edition, Bloch
Resources II
You are expected to read everything that is assigned. If you don’t:
- Do plan on failing.
- Do not plan on sympathy.
Help
Don’t be afraid to ask questions!
I am available during my office hours and online throughout the day via email and the #csc430 slack channel.
Additional office hours can be planned in advance, so contact me!
Help II
Don’t be afraid to ask questions!
Help III
Don’t be afraid to ask questions!
Important Class Policies
- Late submission penalty: 50%
- Plagiarism will be punished as severely as possible
Staying Up To Date
Canvas will be used to handle the general organization of the course and all critical announcements.
Other reminders, notes, etc. may be distributed via twitter @msupwright4 and slack.
Final Note
My goal is to push you hard. Easy classes are not worth the money you are paying and a degree with no actual skills is worthless.
Be responsible. Ask questions. Do your work.
How You Code Now
Why Are We Here?
To understand why this class exists, we need to first analyze how you code now, and then we can talk about why this does not scale beyond the classroom.
Code Volume
Most of your coding experience probably consists of projects with less than 100 lines of code.
How do you manage this code?
Code Volume II
Code Volume III
Code Volume IV
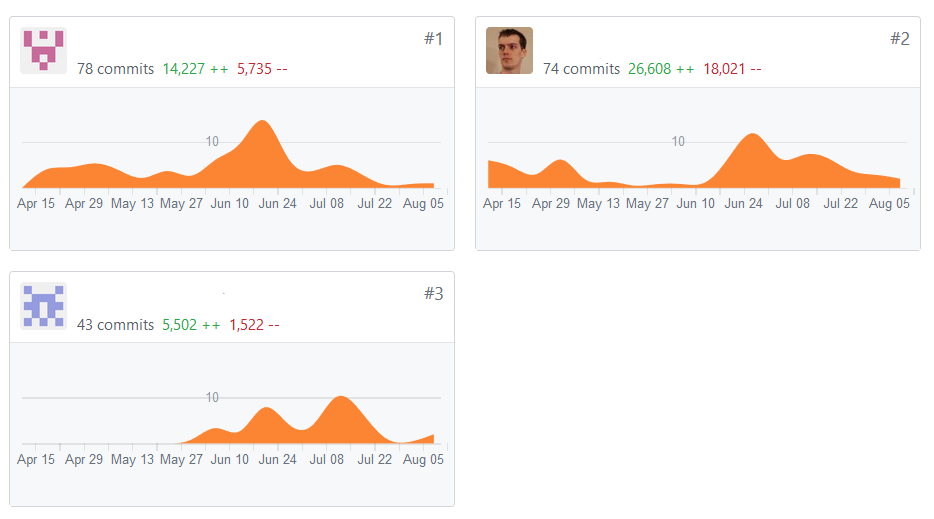
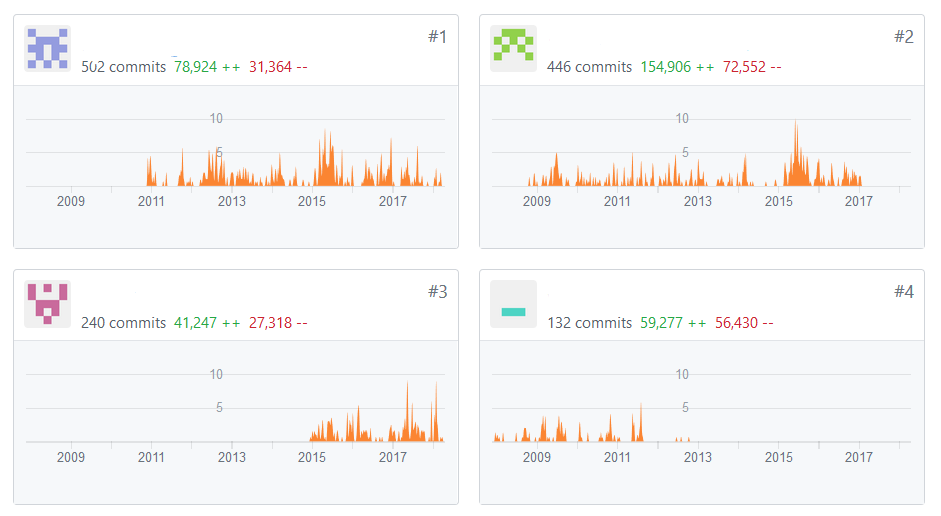
Some line counts for a few projects I work on:
- 20,185
- 269,924
- 271,335
- 173,568
Code Volume V
At these sizes, just working with the code (distributing, sharing, etc.) becomes a non trivial task.
We need a way to backup our code, track changes, and avoid conflicts with coworkers–at scale.
Testing
How do you test your course projects?
Testing II
Manually testing large codebases is, literally, not possible without doing a poor job.
The number of paths in your code to test grows exponentially! If the time you spend testing does not, then you are not testing your code.
Testing III
Even writing tests for large codebases is not possible if the code is written poorly.
Accordingly, we need to automate testing and write our code in a way that makes it feasible to write sufficient tests.
Building
How do you build your code?
Do you even know how you build your code?
Building II
As projects grow in size and complexity, even compiling, building, and deploying your code becomes a problem.
We can not rely on manual steps!
Building III
Instead, we must automate the build process (including testing!) to ensure that we can deliver code in a reproducible, safe way.
Ideally, we automate deployment as well.
Maintenance
How hard is it to maintain your code after a year?
You don’t know, because you throw it away after a week!
Maintenance II
In the real world, your code will live for years (or decades) and will have to be maintainable by the unlucky individual that gets stuck with your legacy code.
Maintenance III
Often, you are that unlucky individual.
Also often, you will not even understand your code if you are not careful with how you write it.
Maintenance IV

Solution
We can largely conquer these problems (and more) by simply caring about our code and automating all the things.
Course Thesis
Humans suck at coding and we must humbly accept all of the help we can get from tools, processes, etc.
Intro To Maven
Maven
According to its own website…
Apache Maven is a software project management and comprehension tool […] can manage a project’s build, reporting and documentation from a central piece of information
Maven II
We will boil that down to the following, though:
Maven is a dependency management and build tool.
Dependency Management
What is dependency management?
Dependency Management II
Code you work on for your courses is often completely self contained, in one or two class files.
You will typically only be importing other classes from the standard library.
Dependency Management III
In a real world project, though, you will typically be relying on a significant amount of code written by others.
Dependency Management IV
This code will be packaged in jar files which you will need to have available when building and distributing your code.
Dependency Management V
In the bad old days, this meant:
- You had to find the libraries
- You had to download them
- You had to keep track of them
- You had to ensure their dependencies are included
- You have to make sure to include them properly when compiling you code
Dependency Management VI
This may not sound to bad, but on large scale projects, this can be a huge source of problems!
Dependency Management VII
A dependency manager will allow you to provide a small amount of configuration, and it will then handle all of these problems for you in an automated manner.
Build Tools
When we talk about a build tool, we are generically referring to any tool that allows you to provide a configuration (or script), which can then handle all build steps that are necessary to produce your end product.
Build Tools II
For instance, you could use a build tool to trigger dependency management, compile your code, execute automated tests, package your compiled code, and more!
Automation
A keep theme here is automation.
If our build process is too complicated, we will forget steps and make mistakes.
This will lead to inconsistencies and errors.
Automation II
Complex manual processes also make it difficult to work with collaborators, because it takes significant work just to get the code running the same on all developer machines.
Automation III
Instead, we use a clear, precise configuration and feed it to a build tool to guarantee that we have reproducibility anywhere our code is built.
This also allows us to reduce our build process to a single command!
Maven III
There are usually multiple build tools that can be used for any given programming language, but Maven is one of the most commonly used in the Java world.
You may be interested in becoming familiar with Gradle as well, though.
Project Object Model
Maven relies on a configuration called a Project Object Model (POM) file.
Our main concern at this point is how to configure dependencies.
For simple projects, the building works out of the box!
Coordinates
To add a dependency, we simply need to provide the group id, artifact id and version of the library you want to use.
We call these the coordinates of the artifact.
Coordinates II
For example, we might add a dependency on a course library like:
<dependencies>
<dependency>
<groupId>edu.murraystate</groupId>
<artifactId>BlobAPI</artifactId>
<version>1.0</artifactId>
</dependency>
</dependencies>
Transitivity
Note that, when you add a dependency, it may also need its own dependencies.
Fortunately, Maven artifacts are packaged with their own POM file, so Maven will go ahead and download all dependencies transitively.
Repositories
Maven is configured, by default, to pull artifacts from Maven Central, which is a public, centralized artifact repository.
You may, however, need to use custom, private repositories.
Repositories II
<repositories>
<repository>
<id>BlobAPI-mvn-repo</id>
<url>https://raw.github.com/MSUCSIS/csc430-maven/mvn-repo/</url>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
</snapshots>
</repository>
</repositories>
Design Patterns
Design Patterns
Design patterns are, ultimately, nothing more than the result of applying a few object oriented principles which you should try to follow.
Design Patterns II
We will be learning those principles, but it is also good to study some of the patterns that arise from their use so that we don’t have to reinvent the wheel.
Design Patterns III
Learning established patterns allow you to quickly get to a solution, and they also provide you and other developers with a shared vocabulary that can be used to discuss your code.
Design Patterns Are Garbage?
During the semester, we will also be discussing how design patterns are actually kind of awful and may be seen as a “least awful” solution to problems in many cases.
Strategy Pattern
The strategy pattern defines a family of algorithms, encapsulates each, and makes them interchangeable. A strategy lets the algorithm vary independent from clients that use it
Strategy Pattern II
Before we take that definition apart, let’s take a look at the object oriented principles that lead to this pattern:
- Encapsulate what varies
- Program to interfaces
- Favor composition over inheritance
Encapsulate What Varies
Modifying code is usually pretty dangerous, because it can introduce regressions in your code.
Encapsulate What Varies II
If we do not properly encapsulate our code, then simple changes can have far reaching impact.
Accordingly, we would prefer to identify behavior that may vary in our code and isolate it from code that does not vary.
Encapsulate What Varies III
If we do this successfully, then the non varying code can be written, tested, and left alone forever.
…assuming our testing was sufficient
Example
For instance, let’s assume we have the following code
public class Duck{
private final int id;
public Duck(final int id{
this.id = id;
}
public String fly(){
// Let's imagine this is a more complex computation
return "I'm flying";
}
public int getId(){ return id; }
}
Example II
In this example, we can be relatively sure that the id related code will not change. However, it is not unlikely that different ducks might fly differently.
Example III
So, we might do this instead
public class Duck{
private final int id;
private final FlyBehavior flyer = new FlyBehavior();
public Duck(final int id){
this.id = id;
}
public String fly(){ return flyer.fly(); }
public int getId(){ return id; }
}
Example IV
public class FlyBehavior{
public String fly(){
return "I'm flying";
}
}
Now, if the flying behavior needs to change, we still never have to handle the Duck class again (almost…).
Example V
We still have a slight problem. Our Duck can only store the class FlyBehavior, so the result isn’t that flexible.
How can we support different flying behaviors?
Program to an Interface
If we write code which uses specific, concrete types, we are stuck with those types and have to manually modify our code, duplicate code and do other awful things to use other types.
Program to an Interface II
If, instead, we program to more abstract interfaces, we can modify the behavior of our code, without modifying the code itself.
Program to an Interface III
Note that, in this context, interface refers to a conceptual interface which can be coded in the form of
- an interface
- an abstract class
- a common super type
- a function signature
Example VI
public class Duck{
private final int id;
private final FlyBehavior flyer;
public Duck(final int id, final FlyBehavior flyer){
this.id = id;
this.flyer = flyer;
}
public String fly(){ return flyer.fly(); }
public int getId(){ return id; }
}
Example VII
Now, we can create various subclasses for FlyBehavior and swap them in and out to customize how ducks fly.
Even cooler, we can do this at runtime!
Favor Composition
When we want to extend the behavior of our code, we typically have two ways to do it. We can either use inheritance or composition.
Inheritance
Using inheritance, A class A can extend another class B and override or add methods to obtain the desired behavior.
We often say that such an instance of A “is a” B.
Composition
We could instead compose objects and include a field of type C inside of a class B and the use that to change the behavior of the class B.
In this case, we would say that B “has a” C
Favor Composition II
We will learn that it is often valuable to write software so that different components are “decoupled” from each other. This is almost always easier when using composition.
Strategy Pattern III
At this point, we have reached a nice clean solution which is, in name, the strategy pattern.
As you see, we were able to reach this point only using basic principles, but it would have been easier to just jump straight to this design!
When To Use
You should consider using the strategy pattern when:
- Many classes differ only in some type of behavior
- You need different variations of an algorithm
- An algorithm uses data that clients shouldn’t know about
- A class defines many behaviors selected by a conditional
Problems
Some drawbacks of the strategy pattern include:
- clients must be familiar with the strategies
- various strategies may require different parameters
- If stateful, there could be a large number of classes required
Is It Garbage?
We know that an interface that contains a single method can be replaced with a lambda expression.
This means we don’t have to define a special interface for the strategy: we just need to specify a general function interface as a parameter.
Is It Garbage? II
Additionally, we are passing strategies into constructors, but we could simply pass them into the methods where they are needed.
Storing them in a field is just a convenience.
Is It Garbage? III
At this point, we have essentially reached the basic concept of higher ordered functions
A higher ordered function is a function which takes another function as a parameter
Is It Garbage? IV
If the strategy pattern is basically just a complicated implementation of higher ordered functions, then what is the point of jumping through extra hoops?
As Java incorporates more functional concepts, design patterns like this start to become much less interesting.
Testing Intro
Testing
No matter how good you are, you will make mistakes. Probably more mistakes than you will ever know.
Testing II
Accordingly, it is necessary to not only do what you can to not make mistakes, but also to rigorously test your code to confirm that you were successful.
Testing III
You will still have bugs, though…
Unit Tests
Our first line of defense will be unit tests: small, directed tests aimed to check whether or not the smallest units of our code are working correctly.
Unit Tests II
Ideally, our development process would be driven by our unit tests.
This concept is referred to as Test Driven Development (TDD).
Test Driven Development
- First Law: Don’t write production code until you have failing tests
- Second Law: You may not write more test code than is necessary to create a failure
- Third Law: You may not write more code than is necessary to fix the failures.
Test Driven Development II
Alternatively, we can restate these laws as the following list of steps:
- Write a test that fails
- Fix the failure with minimal changes
- Refactor and repeat
Test Driven Development III
If we do this well, then we know that all of the desired functionality has been tested, because, otherwise, it would not exist.
Also, we now have a safety net to protect us from regressions in the code base. If someone breaks our code, we should immediately know because of failing tests.
Test Driven Development IV
Unfortunately, it doesn’t always go so smoothly. For instance, we have to write our tests correctly, we have to test for unintended results as well as intended results (which is more difficult to do!), and, in some cases, we can’t write unit tests!
Swiss Cheese Model
In many fields, safety relies on the “Swiss Cheese” model:
There will always be holes in any layer of safety that you implement, but if you have enough layers in places, it greatly decreases the odds that a hole will exist in the entire system.
Swiss Cheese Model II
So, we try to use our brains to make sure we right good code, and we try to write good tests. We will fail at both, but will hopefully come closer to eliminating bugs than if we didn’t test at all.
Static Typing
Another simple layer to add, which a lot of people overlook, is using the type system to model your problems.
Static Typing II
Strong Static Typing can often give you similar benefits as unit testing.
- The more you model your problem with types, the fewer invalid states will compile
- …and the easier it is to refactor code with confidence
Static Typing III
In languages like Agda, Idris, Coq, you can model problems so completely that compilation “guarantees” correctness (sort of…), because invalid states can not be compiled.
In these languages, you are basically writing proofs.
Swiss Cheese Model III
This gives us:
- Our coding skills
- The type system/compiler
- Unit tests
To combat bugs in our code
Unit Tests III
So, our unit tests will allow us to ensure code performs as expected, to modify code without causing regressions, and empowers us to refactor our and improve our code without fear.
But how do we write unit tests…
Writing Tests
Unit Tests Are Code
Obviously. The point, though, is that you should use all of the principles you apply to writing good code in general when writing unit tests. You will need to maintain, fix, and improve tests over time just like all other code!
Unit Tests Are Code II
If you don’t follow best practices, updating tests will become such a nightmare that you will simply start deleting tests or just stop testing at all. Then regressions creep in and the game is over.
F.I.R.S.T
- Fast: or they won’t be executed
- Independent: isolate tests so it’s clear what causes failures
- Repeatable: it should be trivial to test again and again
- Self-Validating: test should be reduced to pass/fail without need for human validation
- Timely: should be written before/along with code being tested
What To Test
First, we need to identify what a given unit should do.
This sounds simple, but it isn’t!
We can easily create tests for the common, obvious cases, but we must also test for the boundary cases.
Boundaries
For instance, if we are implementing a function to calculate the area of a rectangle given its height and width, what inputs should we test?
First, we would do something obvious like area(10,5)=50.
Boundaries II
But what happens if we are given negative values? What if we are given zeros?
We often forget about these types of inputs when writing code and just assume we will “obvious” inputs.
Boundaries III
In this particular case, the logic is simple enough that we can easily address the problem with a couple of tests and some branching in our code.
In general, though, we really need to focus on our domains.
Boundaries IV
In general, for an integer parameter, we should probably consider the following values:
- positive values
- negative values
- zeros
- one
- negative one
Boundaries V
If we know we are using modular arithmetic, then we may want to test one representative from each congruence class as well.
If we are working with mod m, then maybe a good set of tests would be
-m-1, -m, …, -2, -1, 0, 1, 2, …, m, m+1
Boundaries VI
Basically, what you want to do is think about the input types, identify boundary values that are likely to cause different behavior, then test those boundary values, near those boundary values, and far away from the boundaries in all directions.
Boundaries VII
And don’t forget null values!
Boundaries VIII
So what would good inputs be for a method with a List input?
What about a method that takes a Point as input?
What about String inputs?
Assertions
Once we have decided what we need to test, we will write a single unit test for each interesting input and make an assertion about what its output should be.
Assertions II
Ideally, you should have one assertion per test. if not, all assertions should at least be testing one aspect of your code.
Another Problem
How can we test code that requires a database lookup?
Mocking
Problem II
As we stated previously, we want to isolate the code being tested from the rest of the code base.
A database lookup, though, will require database libraries, data model code, a running database, proper setup of the data in the database, etc.
Isolate At The Boundary
The first step should be to isolate the database code from your code. You can do this by providing some interface that matches your data model and provides convenience methods for lookups.
Isolate At The Boundary II
All SQL, driver configuration, etc. will be hidden behind this interface, so your code that requires a lookup may simply call something like:
final User u = db.lookupUserById(10);
Isolate At The Boundary III
The db object can then be passed into our object or method and, since we have “programmed to an interface,” we can replace this object with any instance of the same interface.
Mocking
To properly isolate the our code from the database lookup when testing, we could provide a mock for the database lookup object.
In other words, we can create a class that matches the necessary interface, but does not actually interact with a database!
Mocking II
In our unit test, we will create a mock that is configured to return a specific instance of the User class when the lookup method is called with the value 10, and then we can write our test with the assumption that the lookup succeeds!
Mocking III
If we mock all dependencies in a method or class using this, approach, then we know that any errors are caused solely by the method or class logic itself, and not by dependencies.
Mocking IV
This also makes it easier to write tests, because a lot of code my be required to create real instances that you could use, but mocks are usually rather trivial to create.
Observer Pattern
Observer Pattern
defines a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically
AKA: Publish-Subscribe, Dependents
OO Principle: Loose Coupling
Strive for loosely coupled designs between objects that interact.
Loose Coupling
- Allows objects to interact with minimal knowledge
- Changes to one component won’t impact another (within reason)
- Components can be added without requiring changes to code
- Turns dependencies into a runtime property instead of a static property
OO Principles
We will also be utilizing the previous principles we learned:
- Encapsulate what varies
- Favor composition over inheritance
- Program to interfaces
Strategy Pattern
Let’s think about how the strategy pattern works real quick, and see if we can derive the observer pattern from it.
Strategy Pattern II
Whenever some action happens (e.g., a method call), we delegate to a strategy which encapsulates the desired behavior.
Observer Pattern II
Whenever some action happens (e.g., an update), we notify an observer which encapsulates the dependent behavior.
Sounds familiar…
Observer Pattern III
As long as we only have one dependency, we can see that the observer pattern and strategy pattern are basically identical.
One-To-Many
So, how do we incorporate multiple dependencies into our strategy pattern?
We just add the ability to provide multiple strategy patterns to a subject!
One-To-Many II
public class Duck{
private final long id;
private final Observer observer1;
private final Observer observer2;
public Duck(long id,Observer o1,Observer o2,Observer o3){
// ...
}
public void fly(){
observer1.notifyOfFlight(id);
observer2.notifyOfFlight(id);
}
}
One-To-Many III
We will also typically provide the ability to subscribe and unsubscribe observers at run times, though this is not particularly different from the strategy pattern (though we often make strategy patterns final).
One-To-Many IV
public class Duck{
private final long id;
private final List<Observer> observers=new ArrayList<>();
public Duck(long id){
this.id = id;
}
//...
}
One-To-Many V
public class Duck{
//...
public void fly(){
for(final Observer o : observers){
o.notifyOfFlight(id);
}
}
}
So just use strategies?
No! While the essence of these two patterns are the same, the use cases for the observer pattern often have common requirements (like (un)subscribing) and specific semantics related to when notifications should occur, etc.
Strategy vs. Observer
Observers…
- Almost always have a greater number of dependents
- Have a looser coupling, because the intent of the dependent is unknown
- Focus more on the dependency and less on the computation
I.e., a subject does not care what the dependency is doing!
When To Use
You should consider using the observer pattern when:
- An abstraction has two aspects where one is dependent on the other.
- When a change in one components requires changes in others, but which/how many is not known.
- When objects should be able to send/receive data without assumptions.
Problems
One issue with the observer pattern is that we really have no idea what dependents are doing. If an observer performs a large amount of computation, or cascades updates to its own observers, you can cause a huge performance hit!
Implementation Details
We also must decide whether we want to use a pull model or a push model for our updates.
Pull
- Observers only receive an update notification and reference to the subject
- Observers may then query the subject for just the data they need
- Embraces the subjects ignorance of its dependents’ behaviors
- Could be less efficient for the observer, due to the overhead of gathering data
Push
- All of the needed data is pushed to all observers
- Makes the coupling a bit tighter, perhaps
- Gives the subject more control over the data
Decorator Pattern
The Decorator Pattern
Attaches additional responsibilities to an object dynamically. Decorators provide a flexible alternative to subclassing for extending functionality.
AKA: Wrapper
OO Principle: Open/Closed
Classes should be open for extension, but closed for modification
The Decorator Pattern II
- Allows for extension at runtime.
- Allows you to modify the behavior of a class without actually changing it
- …and without it even being aware of the decorators existence!
Example
public interface Duck{
String fly();
}
Example II
public class BasicDuck implements Duck{
private final FlyStrategy strategy;
public BasicDuck(final FlyStrategy strategy){
this.strategy = strategy;
}
// ...
}
Example III
public class StrongDuck implements Duck{
private final Duck wrapped;
public StrongDuck(final Duck d){
this.wrapped = d;
}
public String fly(){
return wrapped.fly() + wrapped.fly();
}
}
The Decorator Pattern III
- Avoids an explosion of subclasses
- $ |base classes| \times |variations| $ (if we only use one variation)
- $|base classes| \times 2^{|variations|}$ (any combination of variations)
- $\infty$ (if we allow repeated variations)
The Decorator Pattern IV
- Allows for added behavior before/after the components behavior
- Allows for the complete replacement of a component’s behavior
- Allows for enhancement of a given instance of a class.
- Completely transparent to clients (unless they’ve done something ugly)
Transparency
- A decorator and the object it decorates are unique
- They, naturally, are not the same class
- Accordingly, things like referential equality and casting may fail!
When To Use
- Behavior needs to be added to an object instance dynamically and transparently
- Behaviors may need to be removed from an instance
- The number of variations make subclassing impractical (or impossible)
- The class definition is not available for subclassing.
Strategy Vs. Decorator
We can think of a decorator as a skin over an object that changes its behavior. […] The strategy pattern is a good example of a pattern changing the guts.
Strategy Vs. Decorator
- To use a strategy, the client must have knowledge of the strategy interface.
- When using a decorator, the client can be completely ignorant of its existence.
Java Things
String Representation
Java provides a default toString() method for all Objects, but it leaves much to be desired.
So, it’s usually a good idea to override the toString method to give a better String representation.
String Representation II
This is particularly useful when debugging your code, as you can quickly get a summary of the state of an Object without digging into the debugger data.
Building Strings
So, how should you build complex Strings?
For simple cases, it might be fine to do
final String s = "Point(" + x + "," + y + ")";
But it’s mainly fine because the compiler can optimize it. Why might this be bad?
Building Strings II
To make things a bit cleaner, though, you may want to use String.format:
final String template = "Point(%d,%d)";
final String s = String.format(template,x,y);
Building Strings III
For building more complex strings that involve concatenation and iteration, you’re probably better off using a StringBuilder:
final StringBuilder sb = new StringBuilder();
sb.append("Points:");
for(final Point p : points){
sb.append(p.toString());
sb.append(",");
}
sb.setLength(sb.length()-1);
final String s = sb.toString();
Review
What is the difference between calling
p1.equals(p2)
and
p1==p2
What Does Equality Mean?
When we talk about values being equal, we are usually making a lot of assumptions about what that means.
In reality, there is no good, universal definition of equality.
Equality
For instance, all of the following could meet the definition of two points being equal:
- They are stored at the same memory location
- They have the same x and y components
- They represent the same point in space
Which one is correct?
Equality II
Java, by default, assumes that equals means two items are stored at the same memory location. So, in the following code:
final Point p1 = new SimplePoint(10,10);
final Point p2 = new SimplePoint(10,10);
The objects p1 and p2 are not equal!
Structural Equality
Intuitively, this may seem odd. Accordingly, Java allows you to override the equals method and make it work however you want.
Often, the best decision will be to use structural equality: two objects are equivalent if they have the same structure and values.
Equals
For example, we could write the following method:
public boolean equals(final Point other){
if(getX() == other.getX() && getY() == other.getY()){
return true;
}else{
return false;
}
}
Equals II
So, is our equals method good enough?
Equals III
The equals method is actually defined with a parameter of type Object, so we can’t expect to receive a Point!
Also, we have not checked for the possibility of receiving a null value!
Equals IV
public boolean equals(final Object other){
if(!(other instanceof SimplePoint)){
return false;
}else{
final SimplePoint p = (SimplePoint)other;
// Why ==?
return x==p.x && y==p.y;
}
}
Equals V
We can also short circuit the check by adding the following:
if(this==other){
return true;
}
Semantic Equivalence
We could instead attempt to use some sort of semantic equivalence, but it is often dangerous to do so and may not return the intuitive result for your users. For example,
final Currency brl = new BRL(1.0);
final Currency usd = new USD(0.247114);
// Should this be true due to the current fx rate?
brl.equals(usd);
Equals In General
Generally speaking, however we choose to define equals, it should be reflexive, symmetric and transitive.
Which you, of course, remember from CSC-300, right?
Reflexive
\[\forall x : x \equiv x\]In other words, an object must equal itself.
Symmetric
\[\forall a, b : a \equiv b \iff b \equiv a\]In other words, objects must agree on being equal.
Transitive
\[\forall a,b,c : ( a \equiv b \land b \equiv c ) \Rightarrow a \equiv c\]In other words, we can infer equivalence via other equivalences which have an “overlapping” element.
Inheritance
When we use inheritance and add fields to an object, it almost guarantees that we have broken the equals method if we expect it to work with all the parent and child classes.
Immutable Objects
Immutable objects also work really nicely with structural equality, because you can literally swap equal instances with no impact on your code.
(assuming you don’t use ==, or reflection, or something else nasty)
Immutable Objects II
It also means that objects can be re-used. We could, for example, use the exact same Point(0,0) object for every instance of a Duck at that location over time.
Immutable Objects III
If we have a small, finite, number of possibilities, we can just create a pool of Points and never have to allocate a new one!
Immutable Objects IV
This explains the curious Integer.valueOf(int i) method. This:
final Integer x = new Integer(10);
Allocates a new Integer on every call. On the other hand:
final Integer x = Integer.valueOf(10);
Can cache common values and reuse them.
Don’t Forget Hash Code
The hashCode and equals methods are expected to work in concert:
If two objects are “equal”, then they must return the same hash code!
(This does not mean they must have different hash codes if they are unequal!)
Hash Code
With structural equality, this is not difficult: you just need to pass all fields used for equality testing to Objects.hash(…) and it will compute a good hash code for you.
Hash Code II
With more exotic definitions of equality, this becomes very difficult.
Also, with immutable objects, we only really need to compute the code once!
Gotchas
There are a lot of nice ways to shoot yourself in the foot when using Java. Let’s take a look at some reasonable looking code and figure out why it may not be so reasonable.
Equals
public boolean test(final String x){
return x=="something"
}
// ...
System.out.println(test(x));
What output will we see if x has the value “something”?
Equals II
Depending on the code and how the compiler optimizes, we may get true or false. If x gets its value from a literal and the compiler optimizes the code so that duplicate String literals are stored at the same location, we’ll get true. Otherwise, false.
Casting Arrays
How’s this code?
final Object[] objects = {"hello","ola","Hallo"};
final String[] strings = (String[])objects;
Casting Arrays II
It’s awful and it’s guaranteed to throw an exception!
final String[] strings =
Arrays.asList(objects).toArray(new String[]);
Threading
public class X extends Thread{
private boolean go = true;
public void run(){
while(go){
// do something
}
}
public void dontgo(){
go = false;
}
}
Threading II
public static void main(final String[] args){
final Thread t = new X();
t.start();
t.dontgo();
}
Threading III
This code may never stop, because the memory modification from the main thread is not guaranteed to be observed by all other threads (including the actual thread itself!)
It’s only guaranteed to work if we make the variable volatile or insert synchronization code.
More Threading
public class Y{
private int n;
public Y(final int n){
this.n=n;
}
public void test(){
if(n!=n){
throw new AssertionError();
}
}
}
More Threading II
Assuming we are sharing this object with other threads, what will happen when we call test?
Are you sure?
More Threading III
In fact, this may throw an assertion error, because there is no guarantee that both accesses to n will see the same value, even though only one value was assigned! Why?
LOL
public class Lol{
public double value;
}
final Lol = new Lol();
Lol.value = 12121.0;
LOL II
Assuming this object is shared with other threads, what possible values might they see?
LOL III
They could see 0.0, which is the default for a double.
They could see 12121.0, which is what it’s updated to.
…or they could see whatever you get from taking half the bits from 0.0 and half the bits from 12121.0
** LOLOLOLOLOLOL **
Immutable Objects II
Of course, immutable objects using final variables avoids all of these problems!
Takeaway
Programming is awful and there’s no way you can write correct code without a lot of hard work and help from tools, best practices, etc.
Also
Buy Java Concurrency in Practice before you try to write any multi-threaded Java code in the real world.
If you aren’t using Java, make sure you look into the “memory model” of your language: it’s almost guaranteed it’s a horror show as well!
Factory Pattern
OO Principle: Dependency Inversion
Depend upon abstractions. Do not depend on concrete classes.
Dependency Inversion
- Both high level and low level classes should depend on abstractions.
- Variables should not reference concrete classes
- Which means we can’t use new!
- Classes should not derive from concrete classes
- Methods should not override base class implementations
…for some definition of “should”
DI and Factories
With past patterns, we have been abstracting and encapsulating behavior, dependencies, etc. and making them runtime properties, increasing extensibility, etc.
To eliminate coupling introduced by the new operator, we will now abstract and encapsulate object instantiation using factories.
The Factory Method Pattern
Defines an interface for creating an object, but let’s subclasses decide which class to instantiate. The Factory Method Pattern lets a class defer instantiation to a subclass.
AKA: Virtual Constructor
Example
public interface Product{
// ...
}
public class Car implements Product{
// ...
}
public class Boat implements Product{
// ...
}
Example II
public abstract class Producer{
public Product produce(){
Product p = createProduct();
// do stuff with product
return p;
}
protected abstract Product createProduct();
}
Note that the Producer only has dependencies on the Product interface, just like the Car and Boat classes. This class can now be closed for modification since we have inverted our dependencies.
Example III
public CarProducer extends Producer{
protected Product createProduct(){
return new Car();
}
}
public BoatProducer extends Producer{
public Product createProduct(){
return new Boat();
}
}
Factory Method
- Eliminates the need to bind application specific classes in code
- Allows us to close our classes to modification
- Concentrates instantiation into fewer locations
Isolating Problems
A common goal of good design is to simply take the bad stuff you can’t eliminate from your code entirely, and isolate it in the smallest number of locations possible. This applies to:
- object instantiation
- side effects
- instanceof testing
- …
When to use
- When a class can’t anticipate the class of objects it must create
- When a class wants to delegate object instantiation to subclasses
Warning
If the only thing the subclass does is instantiate an object, then maybe we’re just making our lives more difficuly for no reason.
If you are already subclassing, though, then it’s fine.
Abstract Factory Pattern
Provides an interface for creating families of related or dependent objects without specifying their concrete classes.
Abstract Factory Pattern II
- Isolates concrete classes
- Makes it easy to exchange families of classes
- Promotes consistency
When To Use
- A system should be independent of how its products are created
- A system should be configured with one of multiple families of products
- A family of products must be used together
- You want to provide a library of products without exposing their implementation
Warning
If we need to add a new type of product, it can be difficult, because all product families must be updated.
Command Pattern
The Command Pattern
Encapsulates a request as an object, thereby letting you parameterize other objects with different requests, queue or log requests, and support undoable operations
AKA: Action, Transaction
Command Pattern
public interface Command{
public void execute();
}
final Projector projector = new Projector();
final Command projectorOn = new Command(){
public void execute(){
projector.turnOn();
projector.setInput();
}
}
final Button button = new Button(projectorOn);
Command Pattern II
Doesn’t this look familiar?
Command Pattern III
It kind of feels like the strategy pattern, because we’re passing in an algorithm that should be used by the button at runtime.
It also kind of feels like the adapter pattern, because we are adapting the interface of the projector to the Command interface.
Lambdas Again
So, are we doing OO for the sake of OO again? To begin with, we could write:
final Projector projector = new Projector();
final Button button = new Button(
()->{
projector.turnOn();
projector.setInput();
});
Lambdas Again II
If we write our methods so that they return the object they are called on to simulate function composition, we get:
final Projector projector = new Projector();
final Button button =
new Button(()->projector.turnOn().setInput());
Question
Could we instead write:
final Projector projector = new Projector();
final Button button =
new Button(projector.turnOn().setInput());
Lazy Execution
We can’t make this change, because the point of the Command pattern is to decouple the object that performs a computation from the object that invokes that computation.
In other words, we are deferring the execution of the computation until it is needed.
Command Pattern IV
We can extend our commands to do some other interesting things. For instance, we can provide an inverse operation to provide support for undoing operations.
public interface Command{
public void execute();
public void undo();
}
Command Pattern V
final Button button = new Button(new Command(){
private Input prevInput = null; // LOLOLOLOLOL
public void execute(){
prevInput=projector.getInput();
projector.nextInput();
}
public void undo(){
if(prevInput!=null){
projector.setInput(prevInput);
}
}
});
Macros
The logic we put in our commands is also free to contain references to other commands, which means we could build macros!
public class MacroCommand implements Command{
private final List<Command> commands;
public MacroCommand(final List<Command> commands){
this.commands=commands;
}
public void execute(){
for(final Command cmd : commands){
cmd.execute();
}
}
}
Macros II
final List<Command> commands = new ArrayList<>;
commands.add(new Command(){/*turn on projector*/});
commands.add(new Command(){/*set projector to hdmi*/});
commands.add(new Command(){/*turn on bluray player*/});
commands.add(new Command(){/*turn off lights*/});
final Command watchMovie = new MacroCommand(commands);
Command Pattern VI
- Object oriented replacement for callbacks
- Decouples the invoking object from the operation implementing object
- Commands are first class objects
- We can queue them
- We can create transactions
- Can be used for event logging
- …and more
When To Use
- You need to parameterize objects with an action to perform
- You need to specify, queue, and execute requests at different time
- You need to support undo, redo, etc.
- You need to support logging changes to recreate state in case of failure
- You need to use high level operations which consist of several primitive operations
Warning
Undo operations can quickly get out of hand, as you may need to store a lot of state if you support multiple levels of undo!
Adapter Pattern
Adapters
We briefly discussed adapters earlier in the semester when discussing decorators, but didn’t go into much detail, because there is very little difference. For the sake of completeness, let’s review briefly.
The Adapter Pattern
Converts the interface of a class to another interface expected by clients. Lets classes work together that couldn’t otherwise because of incompatible interfaces
AKA: Wrapper
Adapters II
As mentioned before, the main difference between decorators and adapters is that decorators implement the same interface as what is being wrapped, while adapters use a different interface.
Adapters III
Note that when using adapters we lose the benefits of transparency that we obtain from using decorators.
Accordingly, we can “stack” decorators, but can only have one adapter of a given kind.
The Facade Pattern
Provides a unified interface to a set of interfaces in a subsystem. Defines a higher level interface that makes the subsystems easier to use.
Facades
We can view facades as, basically, adapters which adapt multiple complex interfaces to a single, simple interface. In other words, they will often “wrap” more than one object, and expose their functionality in an adapted interface.
Template Method Pattern
Template Method
Defines the skeleton of an algorithm, deferring some steps to subclasses. Template methods let subclasses redefine certain steps of an algorithm without changing the algorithm’s structure.
Template Method II
public abstract class CaffeineBeverage{
// ...
public void prepare(){
boilWater();
brew();
pourInCup();
addExtras();
}
// ...
}
High level algorithm. Almost like pseudo code!
Template Method III
So, at a high level, we know who to make a caffeinated beverage, but we haven’t provided any details about any of the steps.
What changes if we want to make tea versus making coffee?
Do all steps change?
Template Method IV
For the steps that won’t (likely) change, we can go ahead and provide the common implementation
Template Method V
public abstract class CaffeineBeverage{
// ...
public void boilWater(){
// Boil the water...
}
public void pourInCup(){
// Pour into a cup
}
// ...
}
Template Method VI
For the remaining steps which we expect to be specific to a subclass, we can provide a simple abstract method signature.
Note that, not only do we expect them to defined in the subclass, we actually force this by making them abstract.
Template Method VII
public abstract class CaffeineBeverage{
// ...
public abstract void brew();
public abstract void addExtras();
}
Template Method VIII
Now, we can implement specific, concrete algorithms using this template by subclassing.
Template Method IX
public class Coffee extends CaffeineBeverage{
public void brew(){
// Brew in a coffee specific way
}
public void addExtras(){
// Add cream and other coffeeish things
}
}
Template Method X
public class Tea extends CaffeineBeverage{
public void brew(){
// Brew in a tea specific way
}
public void addExtras(){
// Add lemon and things
}
}
OO Principle: Hollywood Principle
Don’t call us, we’ll call you
Hollywood Principle
- High level components call low level components
- …but without creating dependencies on them
Other Patterns
How is this similar to other patterns?
When To Use
- To implement variant and invariant parts of algorithms separately
- When common behavior needs to be factored out of several subclasses
- To restrict subclass extension via “hooks”
Implementation
- Think about what subclasses must implement, and make those steps abstract
- … otherwise, provide a default implementation (which might do nothing!)
- Try to reduce the number of required implementations.
Iterator/Composite Patterns
The Iterator Pattern
Provides a way to access the elements of an aggregate object sequentially without exposing its underlying representation.
AKA: Cursor
Iterator Interface
public interface Iterator {
public abstract hasNext();
public abstract next();
public abstract remove();
}
Iterator
- Encapsulates the concept of iteration
- Simple loops
- Multi dimensional loops
- Tree traversals
- Any other structures…
- Hides implementation details
- Provides for multiple types of traversals
- Provides a uniform interface for different aggregate types
Implementation
- Internal or external?
- Should the iteration algorithm be defined in the iterator or aggregate?
- How are concurrent modifications handled?
The Composite Pattern
Composes objects into tree structures to represent part-whole hierarchies. Composite lets clients treat individual objects and compositions of objects uniformly.
Composite
public interface Graphic{
public abstract void draw();
public abstract void add(Graphic g);
}
Composite II
public class Picture implements Graphic{
final List<Graphic> graphics;
public void draw(){
for(final Graphic g : graphics){
g.draw();
}
}
public void add(final Graphic g){
graphics.add(g);
}
}
Composite III
public class Rectangle implements Graphic{
// [...]
}
public class Line implements Graphic{
// [...]
}
public class Text implements Graphic{
// [...]
}
Composite Pattern
- Provides a simple interface for recursive structures
- Makes it easy to add new kinds of components
When to use
- You want to represent part-whole hierarchies
- You want clients to treat all objects in a complex structure uniformly
Warning
A composite type necessarily represents a union of interfaces. This means that only a subset of the interface might be valid at a given time. Accordingly, the type system becomes much less useful and runtime checks will be required.
State Pattern
The State Pattern
Allows an object to alter its behavior when its internal state changes. The object will appear to change its class.
KA: Objects For States
State Machines
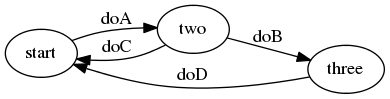
(You remember these, right?)
State Machines
public enum State {
START,TWO,THREE,ERROR;
}
State Machines
public class StateMachine {
State state = START;
public void doA(){
if(state==START){
state=TWO;
}else if(state==TWO){
state=ERROR;
}else if(state==THREE){
state=ERROR;
}
}
//public void doB()
//public void doC()
//public void doD()
}
State Machines
What happens when we need to make a change to the state machine?
Encapsulate What Varies
The State Pattern
- Localize the behavior of each state into its own class
- Each state closed for modification, client open for extension
The State Pattern
- Define state interface
- Define concrete state class for each state
- Delegate transitions, behavior, etc. to states
State Interface
public interface State {
public void doA();
public void doB();
public void doC();
public void doD();
}
States
public class StartState implements State{
public StartState(StateMachine machine){
// initialize things...
}
public void doA(){ machine.state=machine.getStateTwo(); }
public void doB(){ machine.state=machine.getErrorState(); }
public void doC(){ machine.state=machine.getErrorState(); }
public void doD(){ machine.state=machine.getErrorState(); }
}
State Machine
public class StateMachine{
State start = new StartState(this);
//... initialize other states
State state = start; // initial state
public void doA(){state.doA()};
public void doB(){state.doB()};
public void doC(){state.doC()};
public void doD(){state.doD()};
}
State vs Strategy
- The client chooses the behavior with a strategy
- The state is often chosen by prior states
- Client is much less aware of the behavior it is using
- Strategies tend to not change
Warning
- States may be tightly coupled
- Including state in state objects may require a large number of states
Another Way To State
public class StateMachine{
State state = START;
F<Unit,State>[Input][State] fsm = // wut?
public void nextInput(Input i){
// Use current state and input to look up
// a function which will perform the transition
F<Unit,State> f = fsm[i][state];
// apply the function for the new state
state = f();
}
}
Another Way To State
fsm[START][A]= {
// do some side effects, print messages, get crazy
return TWO;
}
fsm[TWO][B]= {
// do some side effects, print messages, get crazy
return THREE;
}
Proxy Pattern
Proxy Pattern
Provides a surrogate or placeholder for another object to control access to it
AKA: Surrogate
Proxy Pattern II
More concretely, the proxy pattern creates a representative of some other resource or object in order to hide problems with interacting directly with that resource.
Proxy Pattern III
For example, we may not want to interact directly with an object, because:
- it may be expensive to create/use
- it may be a remote resource
- it may be a sensitive resource for which we should control access
Virtual Proxy
A virtual proxy is a type of proxy we may want to use to defer the cost of creating or interacting with a resource until it is needed.
Lazy Loading, Again
This may already remind you of the concept of lazy evaluation or lazy loading that we discussed earlier in the semester.
Virtual Proxy II
Imagine, for example, that we want to display a gallery of images in an application, but some images may be loaded remotely from the internet.
Virtual Proxy III
We could create a list of Image objects for our gallery and we could then iterate through the list to draw the images on the screen.
Example
public class URLImage implements Image{
private final Image image;
public URLImage(URL url){
this.image = load(url);
}
//...
}
Virtual Proxy IV
When we create the Image objects, though, we will have to wait for images to be loaded from the internet!
We can not even start drawing images in the gallery until all image data has been downloaded.
Virtual Proxy V
Instead, we could create a virtual proxy for images that need to be loaded from the internet which only store the URL.
We can create these quickly, then get started actually drawing our gallery without being delayed by download times.
Virtual Proxy VI
Of course, we will still encounter delays when drawing proxied images.
Our proxies can be smart, though, so we can create a thread to do download and draw the actual image. In the meantime, we can draw a temporary image!
Example II
public class ImageProxy implements Image {
final URL url;
public ImageProxy(final URL url){
this.url = url;
}
public void draw(){
// draw temporary image
// start thread which will load, then draw real image
}
Example III
Even better, we can cache to avoid downloading the image again:
public void draw(){
if(image !=null){
image.draw();
}else{
// draw temporary image
// start download/draw thread
}
}
Remote Proxy
Another common use of proxies is to create a local object instance that corresponds to a resource or instance on another machine so that we can interact with that resource as if it were on our machine.
Without A Proxy
If we don’t want to use a proxy, but need to trigger a computation on another machine, what can we do?
First, they need to expose the function to us somehow. A common approach would be to use the HTTP protocol.
Without A Proxy II
Then we could create a JSON input like:
{
"a":100,
"b":200
}
And send it to http://someserver.com/addition, which would, perhaps, return:
{
"result":300
}
Without A Proxy III
We also need to create the necessary HTTP client, etc.
This is a lot of tedious work which should not be exposed to users of our code!
Remote Proxy II
Instead, we could create a class which represents the computations available on the remote server and hide all of the HTTP interactions there.
Example IV
public class ServerProxy{
private HttpClient client;
public ServerProxy(URL url){
client = new HttpClient(url);
}
public int add(int a, int b){
String json = buildAddReqBody(a,b);
Response response = client.get("/add", json);
int sum = extractSumFromRessponse(response);
return sum;
}
}
Example V
Now we can create a single instance of the proxy for our application:
ServerProxy proxy = new ServerProxy(url);
And anywhere we need to access the remote computation, we just interact with the local proxy instance!
int sum1 = proxy.add(10,20);
int sum2 = proxy.add(100,200);
Protection Proxy
Another interesting case is when we want to add additional protection to a resource or an object.
Protection Proxy II
This pattern is more similar to the decorator pattern, as we’re wrapping some instance and adding authentication, authorization or something else to control if the actual interaction will be allowed.
Proxy vs Decorator
The intent of a decorator is to add behavior transparently.
The intent of a proxy is to handle delegation of behavior.
Builder Pattern
Builder Pattern
Separate the construction of a complex object from its representation so that the same construction process can create different representations
Complex Objects
We will often have classes which require a large number of parameters or which have a large number of optional parameters. It may be difficult to handle these cases with a single constructor.
Complex Objects II
In other cases, we may have classes with inherently complex structures, like trees, graphs, etc.
Optional Parameters
Let’s assume that we have to have some contact information for a Customer, but we don’t care what kind.
public class Customer {
private final String userName;
private final String phoneNumber;
private final String email:
}
In other words, we must have at least a phone number or an email, but do not require both.
Optional Parameters II
One solution would be to provide constructors for all possibilities:
public Customer(final String userName, final String phoneNumber){}
public Customer(final String userName, final String email){}
public Customer(final String userName,
final String phoneNumber,
final String email){}
Note: we could use the third constructor, but passing in null values, but that is a bad design!
Optional Parameters III
This leads to a poor user experience when the number of parameters and the conditions grows, as we have to create a very large number of constructors that the user must sift through.
Builder
Alternatively, we could use a Builder:
public class Builder {
private String user=null;
private String phone=null;
private String email=null;
public Builder setUserName(String user){this.user=user;}
public Builder setPhone(String phone){this.phone=phone;}
public Builder setEmail(String email){this.email=email;}
public Customer build(){
if(user!=null && (phone!=null || email!=null)){
return Customer(user,phone,email);
}else{
throw new IllegalArgumentException("Invalid parameters!");
}
}
}
Builder II
Now we can create a Customer in a more intuitive way:
final Customer customer =
new Builder()
.setUserName("pwright4")
.setEmail("pwright4@murraystate.edu")
.build();
We don’t have to find the appropriate constructor and order for the parameters, we just call the obvious methods for the data we have. If we don’t have the data to create a valid instance, we get an exception.
Problems
This already leads to some other problems, though:
- We don’t know the instantiation is invalid until runtime
- We are assuming there is a constructor with all parameters that we can pass null values into
Builder III
We can solve the first problem with a little more work and using strong static typing:
public class Builder{
public BuilderWithUser setUser(String user){
return new BuilderWithName(user);
}
}
Builder IV
public class BuilderWithUser{
private final String user;
public BuilderWithUser(String user){
this.user = user;
}
public BuilderWithContact setEmail(String email){
return new BuilderWithEmail(user,email,null);
}
public BuilderWithContact setPhone(String phone){
return new BuilderWithPhone(user,null,phone);
}
}
Builder V
public class BuilderWithContact {
private final String user;
private final String email;
private final String phone;
// ...
public BuilderWithContact setEmail(String email){
return new BuilderWithContact(user,email,phone);
}
public BuilderWithContact setPhone(String phone){
return new BuilderWithContact(user,email,phone);
}
public Customer build(){return new Customer(user, email, phone);}
}
Type Safety
Now we have obtained protection from invalid objects by relying on the types to ensure that we can only call build when we have the right data.
However, this enforces an order on the calls and also may not scale well.
Exposed Constructor
The other issue we had was that we’re still exposing a constructor in Customer that accepts all parameters where we are expected to allow null values.
We typically limit the scope of this problem by nesting the Builder inside of the class being built (or use package privacy, etc.) so that we don’t expose the constructor to general users.
Exposed Constructor
public class Customer{
// ...
private Customer(String user, String email, String phone){
//only the Builder can access this constructor!
}
public static class Builder{
//...
}
}
Factories, Again
Another benefit of using the Builder pattern is that it allows us to separate the actual instantiation of an instance from the code that needs it, similar to how factory methods and abstract factories worked.
The end user provides the data, but has no control over the actual instance that is created.
Builders Are Values
Also, note that the builders are objects themselves that can be passed around in your code, so you don’t have to build your instance immediately. You could, for example, provide some data, then pass the builder to another method which will add more data, etc. then only build when you need the actual result.
When To Use
- The algorithm for creating complex objects should be independent of the parts of the object and how they are composed
- The construction process must allow different representations for the object that’s constructed
Visitor Pattern
Visitor Pattern
Represent an operation to be performed on the elements of an object structure. Define new operations without changing the classes of the elements on which it operates
Problem
Imagine that we have defined some classes which can be used to represent arithmetic expressions:
public interface Expression{}
public interface BinOp extends Expression{
Op operator();
Expression left();
Expression right();
}
public interface Val extends Expression{
int get();
}
Problem II
Assuming we have concrete implementations for these interfaces representing multiplication, addition, etc., we could create arithmetic expressions as complex as we wish.
However, we also want to be able to actually perform operations on these expressions.
Evaluation
Suppose we want to evaluate the whole expression tree. We could add methods for this to the interfaces.
public interface Expression{
Val evaluate();
}
public class Mult implements BinOp{
private final Expression left;
private final Expression right
//... constructor, etc.
public Op operator(){return MULT;}
public Expression left(){return left;}
public Expression right(){return right;}
public Val evaluate(){
return left.evaluate * right.evaluate;
}
}
Evaluation II
public class Value implements Val{
private final int value;
//...constructor, etc
public get(){return value};
public evaluate(){return get();}
}
Problem
This works, but it violates the principle of classes being closed to modification. It’s also likely that we will want to do a lot of different things with our expression trees (maybe some we haven’t imagined!), and we will need to modify the interfaces and implementations for each.
Visitor
The visitor pattern allows us to create visitors that can be applied to the expression to perform the desired computation.
Visitor II
public interface Expression{
void accept(Visitor visitor);
}
public class Mult implements Expression{
//...
public void accept(Visitor visitor){
visitor.visitBinOp(this);
}
}
public class Value implements Val{
//...
public void accept(Visitor visitor){
visitor.visitValue(this);
}
}
Visitor III
public interface ExpressionVisitor {
void visitValue(Val value);
void visitBinOp(BinOp operator);
}
Visitor IV
public class Evaluator implements ExpressionVisitor{
private final Stack<Integer> stack = new Stack<Integer>();
void visitValue(Val value){
stack.push(value.get());
}
void visitBinOp(BinOp operator){
operator.left().accept(this);
operator.right().accept(this);
int r = stack.pop();
int l = stack.pop();
int result = operator.op().apply(l,r);
stack.pop();
}
}
Visitor V
Now that the tree supports visitors, we are able to easily add an evaluation operator without touching the actual tree code. We can also add other visitors to perform other computations.
Visitor VI
public class Printer implements ExpressionVisitor{
private final StringBuilder sb = new StringBuilder();
public void visitValue(Val value){
sb.append(value.get());
}
public void visitBinOp(BinOp op){
sb.append("(");
op.left().accept(this);
sb.append(op.toString);
op.right().accept(this);
sb.append(")");
}
}
Visitor VII
public class MachineCoder implements ExpressionVisitor(){
private final StrinbBuilder sb = new StringBuilder();
public void visitValue(Val value){
sb.append("PUSH " + value.get() + "/n");
}
public void visitBinOp(BinOp op){
op.left().accept(this);
op.right().accept(this);
sb.append(op.toString() + "\n");
}
}
Problems
Decoupling the visitors and the structures is nice, but we pay the price when considering the cost of extending the structure if necessary.
If we add a new expression type, for instance an UnaryOp, then we have to add a visit method for this type. This will then require that every visitor be modified!
Problems II
Another issue is that, since the visitor exists completely outside the structure it’s visiting, it necessarily requires that the elements of the structure expose their internal state so that the visitor can perform computations.
This goes against our general preference to encapsulate state.
Mediator Pattern
Mediator Pattern
Define an object that encapsulates how a set of objects interact. Promotes loose coupling by keeping objects from referring to each other explicitly.
Observers
We have talked previously about the Observer pattern and how it allows us to facilitate interaction between an observable and multiple observers while not requiring tight coupling.
However, the observable/observer relationship is typically one-to-many.
Facades
We also discussed how we can use a Facade to bring together multiple components to form a single, cohesive interface.
However, a facade can only send requests to the subsystems; it is not bidirectional.
Mediator
The mediator can be seen as something like a combination of the Observer and Facade patterns which extends them to support many-to-many interactions without tight coupling.
Example
Consider the case where we have a user interface which contains a button and a text field. We could code the text field so that, every time it’s contents are changed, we check to see if it is empty and, if so, gray out the button.
If we click the button, we could code the button so that when it is clicked we clear out the text box.
Example II
However, if we do this with each component directly referencing the other, we have introduced tight coupling and made our code less flexible.
Example III
Alternatively, we could subscribe observers to the text field and to the button, then create a Mediator which would observe and interact with both.
The Mediator would then contain the logic which grays out the button, clears the text, etc.
The components know nothing of each other, yet interact!
Example IV
Of course, this example only includes two components, but the same concept can be extended to several components which gives us our decoupled, many-to-many interactions.
Blob Game
We could even think of our blob Game class being implemented as a Mediator. It could observe multiple blobs and based on those observations, tell the blobs how they should behave.
When To Use
- A set of objects communicate in well-defined but complex ways
- Reusing an object is difficult because it refers to other objects
- A behavior that’s distributed between several classes should be customizable without a lot of subclassing
Clean Coding
Premise
Writing clean code is what you must do in order to call yourself a professional.
There is no reasonable excuse for doing anything less than your best
Y tho?
- The majority of development resources are spent on maintenance (80%)
- The effects of poor code quality multiply as more code is added
- The further you go down the path of garbage coding, the more unlikely it is that you will ever recover
Cost of Poor Code
- Every change (potentially) breaks something
- No change is trivial (even if it should be)
- Simply understanding the code becomes a significant task
- Accordingly, legacy code is often treated as “off limits”
No Turning Back
- Cleaning old code requires significant work
- It’s also a hard sell for management, because it’s not “productive” work
- …though they may fund a rewrite (which can take years)!
- So, instead of getting stuck at that point: be proactive instead
Boy Scout Rule (Kind Of)
Leave code cleaner than you found it
…because…
LeBlanc’s Law
Later equals never
So, what is clean code?
Let’s Start With Names
We want to make sure the names of variables, functions, etc. provide valuable information. Accordingly, they should:
- Reveal intent
- Avoid disinformation
- Make meaningful distinctions
- Avoid encodings
- Use proper domain
Reveal Intent (Bad)
public List<int[]> getThem(){
List<int[]> list1 = new ArrayList<int[]>();
for(int[] x : theList){
if(x[0]==4){
list1.add(x);
}
}
return list1;
}
Reveal Intent (Better)
public List<Cell> getFlaggedCells(){
List<Cell> flaggedCells = new ArrayList<Cell>();
for(Cell cell : gameBoard){
if(cell.isFlagged()){
flaggedCells.add(cell);
}
}
return flaggedCells;
}
Reveal Intent (Betterer)
public Stream<Cell> getFlaggedCells(){
return gameBoard.filter(Cell::isFlagged);
}
Avoid Disinformation (Bad)
Queue<Account> accountList;
Avoid Disinformation (Better)
Queue<Account> accounts;
Make Meaningful Distinctions (Bad)
String productData;
String productInfo;
String productInfo2;
Make Meaningful Distinctions (Better)
String productDescription;
String productSKU;
String productBinNumber;
Avoid Encodings (Bad)
uint8[] arru8NumberList;
PhoneNumber phoneString; // Type changed!
String m_description; // Class member
Use Proper Domain
When possible, use vocabulary from the solution domain (CS Terms). Otherwise, take vocabulary from the problem domain. Don’t make up your own vocabulary!
Names Don’t Actually Matter!
Many people claim that if your code is good, then the names shouldn’t matter. There is some truth to this, but good names can never hurt.
So, aim try to write code that’s good enough to not need names, but provide clear names as well!
Functions
The more code you have to read:
- the less likely you are to understand the code
- the less likely you are to maintain the code
- the harder it will be to test the code
All of those are bad!
Functions Should Be Small
The first rule of functions is that they should be small. The second rule of functions is that they should be smaller than that.
Functions Should Be Small II
Optimal size is not set in stone, but as a rough guide:
- If you can do it with 2-3 lines, great!
- If you have reached 20, maybe rethink things a bit.
- Which means…
- 1 line in a code block is ideal
- Max indentation level is 1 or 2
- Big switch statements are probably a bad idea
Functions Should Do One Thing
You should aim for one level of abstraction.
Rough guide: if you can extract a non redundant function, do it!
Use Good Names (Again)
- Long names are ok
- Much better than short, confusing names
- Much better than long documentation
- Be consistent with your terms, etc.
Parameters
- No parameters is ideal, because they require no thought
- A couple are usually fine
- More than that may require refactoring, because it gets confusing
- Can types alleviate this problem?
- Is it ok for “low level” code?
Parameters II
- Output parameters are not intuitive and should be avoided
- Avoid boolean flags, since you’re just supposed to do one thing!
Side Effects Are Bad
Side effects are a lie. Your function promises to do one thing, but it also does other, hidden things!
Side Effects Are Bad II
Ideally, we would be dealing with pure functions. The same inputs will always give the same result, like you would (usually) expect!
Exceptions
If you have a fair amount of exception handling logic, then that logic should be the one thing your function is doing.
The logic that could be throwing the exception should be its own function!
How Do You Do All Of This?
Often, you don’t. Just start writing awful functions and refactor them as work progresses. Keep refactoring until you are happy with the results.
Code Comments
The proper use of comments is to compensate for our failure to express ourselves in code
If you get the urge to write a lot of comments to explain your code, consider refactoring the code first.
Why Are They Bad?
- The compiler and tests won’t/can’t make sure they are correct
- They rarely change with the code and cease to be correct
- They can eventually become misleading
Good Uses
- Legal notices
- Explaining intent
- Clarifications
- Warnings
- TODOs (but make sure they get DOed)
- Java docs and similar things
Bad Uses
- Redundant information
- Misleading information (may not be intentional)
- Journaling, attribution, old code
- Sectioning code (why are you writing so much code?)
Formatting
Nicely formatted code is easier to work with and understand.
Vertical Formatting
- Smaller is better!
- Less than 200 lines? Less than one screen?
- Arrange by importance
- Important functions at the top
- Secondary functions later
- Use blank lines to separate concepts
- But otherwise, keep code dense
Vertical Distance
- Related concepts should be close to each other
- Variables should be close to their uses
- instance variables at top, because they are used everywhere
- Function callers before callees
Horizontal Formatting
- Keep lines short
- At the very least, never require scrolling!
- Use horizontal spacing to group/separate
- Use indentation consistently
“Proper” Style
A lot of the details are subjective, but what really matters is that your team agrees on them and uses them consistently.
Software Planning
Pleasing The Customer
When working with a client, they will primarily be interested in two things:
- How much will it cost?
- How long with it take?
Pleasing The Customer II
Unfortunately, software developers are terrible at answering these questions.
The goal of software development tools and methodologies is improve our ability to deliver software on time and on budget
How Bad Is It
An IAG study discovered two types of development teams: teams with “probable success” and teams with “improbable success.”
68% of the teams studied were in the “improbably success” class.
How Bad Is It II
Of the 68% of teams with “improbable success”:
- 79% of projects fail
- 50% of projects have two of the following characteristics:
- Time: more than 180% of plan
- Cost: more than 160% of budget
- Functionality: less than 70% of plan
How Bad Is It III
Of the 32% of teams with “probable success”:
- 73% succeed
- …but only 54% of projects are delivered with complete functionality, on time, and on budget.
The Difference
What did the study find was the key difference between the two classes of teams?
The successful teams did a better job of gathering requirements, creating specifications, and planning.
How To Guarantee Failure
The worst way to develop software is to meet with the customer to establish goals, then “go dark” and program furiously until the deadline.
This “Big Bang” methodology is sure to fail.
What Goes Wrong
The crux of the issue with “Big Bang” development is that the assumptions, guesses and even requirements are often misunderstood or simply incorrect!
However, this fact won’t be discovered until the end of the project.
SDLC
To describe various methodologies that attempt to improve upon the “big bang” model, we will use a general model of development steps referred to as the Software Development Life Cycle (SDLC).
SDLC II
The methodologies we will discuss are all variations on the following steps:
- Planning
- Defining Requirements
- Designing Product
- Implementation
- Testing
- Deployment and Maintenance
Planning
During this stage, we begin to understand the scope of the problem, and the general goals that need to be met.
Requirements
At this point, we want to turn our general understanding of the project into a concrete set of requirements which define a successful project.
Design
In this stage, we establish the actual design of the solution which we believe will meet the requirements previously established.
Implementation
After the design is established, we will then implement the design with actual code.
Testing
Once we have completed out implementation, we need to test it and determine whether or not the requirements have been correctly implemented.
Deployment and Maintenance
When we’ve finished testing, we will release the product to the client, then maintain it as additional bugs are discovered and change requests are created.
Waterfall Model
The waterfall model is a somewhat direct implementation of the SDLC stages. In this model, we complete each step completely before moving on to the next step.
Like a waterfall, we don’t go backwards and revisit steps!
Waterfall Model II
This model depends on the existence of static requirements. If the requirements, plannings, etc. are not sufficient, this model can lead to a similar conclusion as the “big bang” model.
Iterative Model
With the iterative model, we add flexibility by establishing requirements up front, then breaking down the requirements into subsets that are completed in different iterations.
Iterative Model
Having a well defined set of requirements in the beginning is still important, but there is more flexibility for accomodating change in this model as most steps are revisited.
Spiral Model
The spiral model can be viewed, roughly, as a repetition of all SDLC steps over and over until the details are all worked out.
Spiral Model II
This model does not require a full specification up front and is very flexible, but it can also get out of handle and “spiral” indefinitely.
Agile Model
The agile model is another iterative process which, more or less, repeats all SDLC steps over and over.
A big difference, though, is that agile focuses less on planning and more on reacting to inevitable changes.
Agile Model II
With this model, we gather somewhat vague user stories and use cases, then quickly design and implement a solution. This solution is then reviewed with the client to determine what has gone wrong, and correct as needed.
Agile Model III
Another interesting aspect of this model is that, to facilitate client review, all iterations are designed to end with a “complete” product. The entire process is, basically, a series of product releases.
Agile Development
Agile Development
As mentioned previously, the Agile methodology is an iterative development process that is designed (in theory) to allow engineers to more accurately estimate their work and respond to unexpected changes.
History
Seventeen people went on a skiing trip and, by the end, decided they had figured out the proper way to develop software.
(This is not a joke)
History II
At the end of their trip, they published The Agile Manifesto, explaining how to properly develop software.
For some reason, it became a buzzword in the industry and everyone had to “do Agile.”
(Though, more often than not, they aren’t actually “doing Agile”)
Anti-Manifesto Manifesto
Be skeptical of anyone peddling manifestos.
Supporting Research
crickets chirp in the background
Why Are We Learning It
- It’s in the course curriculum
- It’s popular enough that you might benefit from learning it
- There might be some bits and pieces worth thinking about
Gathering Requirements
It is difficult to gather requirements, because
- We make assumptions
- Clients may not know what they really want
- Details will be missing
Feedback
In order to reduce the impact of our inability to gather accurate requirements, we will attempt to add continuous feedback to our development process.
Feedback II
We should start obtaining feedback as soon as possible.
In the Agile world, this means as soon as we have a minimum working product.
Sprints
In order to ensure our ability to get continuous feedback, we must be able to deliver working releases of our product to the client.
To accomplish this, we will divide our work into small, “complete” subsets of functionality called “sprints.”
Sprints II
Sprints should be very limited in scope and should always result in working, buildable, and releasable code.
Ideally, your project should build without failure from the beginning and every single commit should do the same.
Sprints III
By limiting the scope of a sprint and by ensuring that our project always builds, we can more easily provide clients with regular, functioning builds to review and to use for providing feedback.
Sprints IV
How do we create these sprints, though?
Gathering Requirements II
First, we want to gather general ideas about what the product should do.
Gathering Requirements III
Next, we should discuss what we think we understand about the project with the client. We should:
- Confirm any assumptions
- Obtain any missing details
- Ask if, in light of the discussion, there are any additional requirements.
Gathering Requirements IV
To help ensure that we don’t miss anything, we may want to brainstorm with the customer. No ideas should be off limits. The goal is to obtain the absolute ideal requirements assuming no limits.
User Stories
Once we have gathered enough informtion from the client, we will create high level user stories to capture the requirements. These should be:
- Short
- Focused
- Customer driven
- From the customer’s perspective
User Stories II
Once we have all of our user stories, we will estimate the level of effort required to implement each, then prioritize them (with the customer).
Then we simply select user stories from this list to fill the time period of our sprint (often a couple of weeks).
Estimation
How, though, do we estimate the level of effort for our user stories?
We use planning poker.
Planning Poker
All team members sit around a table with “poker cards.”
Each card has a time estimate written on it.
The team discusses a user story and everyone “plays” the amount of time they estimate the story will take.
Planning Poker II
If there is no consensus, then the team discusses their estimates and they play another round.
This is continued until a consensus is reached (or until everyone gets tired of arguing with the guy who refuses to change his mind).
Planning Poker III
Then, magically, the consensus opinion is an accurate estimate.
(This is not a joke)
Planning Poker IV
Why might this not work?
When might it work?
Supporting Research II
It appears that many reports about the benefits of Agile development fall into one of two categories:
- Teams that went from no process to agile development
- Teams consisting of very competent members.
For everyone else, the studies that exist don’t seem to support the hype.
The Good Parts
- Since we are bad at gathering requirements, it’s probably wise to expect misunderstandings and obtain feedback
- Treating every two week period as a “release” of “complete” code is probably beneficial, because having code that always builds cleanly makes development and maintenance easier.
Generics
Problem
Suppose we want to create a pair data structure which can store elements of two specific types. In older versions of Java, there were only two options:
- Define multiple pair classes for different type combos
- Define a pair class that can store any types
With Specific Types
public class StringAndImagePair {
private final String a;
private final Image b;
//...
public String a(){
return a;
}
public Image b(){
return b;
}
}
Problem II
This works, but it goes against the general goals we have of writing reusable code, because we have to create a new definition with almost identical code for every pair of types we want to support.
Untyped Data
public class Pair(){
private final Object first;
private final Object second;
//...
public Object first(){
return first;
}
public Object second(){
return second;
}
}
Problem III
This class can be reused for any two types we want, but this code is very dangerous, because it doesn’t effectively capture the types used in the pair.
Problem IV
public void iNeedAPairOfStrings(Pair pairOfStrings){
// Fails at runtime with ClassCastException!
final String first = (String) pairOfStrings.first();
final String second = (String) pairOfStrings.second();
//...
}
// oops!
iNeedAPairOfStrings(new Pair(someArray, someImage));
Problem V
We must check types to make sure the Pair is used
safely.
public void iNeedAPairOfStrings(Pair pairOfStrings){
if(pairOfStrings.first() instanceof String &&
pairOFStrings.second() instanceof String){
//...
}
}
Generics
To resolve this issue, “Generics” were added to Java, which allows for types to be defined with type parameters which specify the concrete types referenced in generic data structure definitions.
Generic Pair
public class Pair<T,U>{
//...
}
We define a generic Pair class which accepts
two type parameters. We can then instantiate different
types using this single definition.
Pair<String,Image> stringAndImage = new Pair<>(someString, someImage);
Pair<String,String> pairOfStrings = new Pair<>("hello","world");
Generic Pair II
public void iNeedAPairOfStrings(Pair<String,String> pair){
//...
}
Now…
// works fine!
iNeedAPairOfStrings(pairOfStrings);
// won't compile!
iNeedAPairOfStrings(stringAndImage);
Generic Pair III
public class Pair<T,U>{
private final T t;
private final U u;
public Pair(T t, U u){
this.t = t;
this.u = u;
}
public T first(){
return t;
}
public U second(){
return u;
}
}
Methods
public class Pair<T,U>{
//...
public <V> Pair<V,U> mapFirst(Function<T,V> f){
return new Pair<>(f.apply(t),u);
}
public <V> Pair<T,V> mapSecond(Function<U,V> f){
return new Pair<>(t,f.apply(u));
}
}
Methods II
public class Pair<T,U>{
//...
public <V,W> Pair<V,W> map(Function<T,V> f, Function<U,W> g){
final V first = f.apply(t);
final W second = g.apply(u);
return new Pair<>(first,second);
}
}
Wildcards
What if we want to write a method that accepts a list of any kind of number?
You might think List<Number> would work for a List<Integer>, but it doesn’t!
List<Integer> is not a subtype of List<Number>.
Wildcards II
To handle this, Java uses wildcards (?).
? extends Type: An upper-bounded wildcard.? super Type: A lower-bounded wildcard.
Wildcard Example
Using a wildcard, we can now write a flexible sum method.
public double sum(List<? extends Number> list) {
double sum = 0.0;
for (Number n : list) {
sum += n.doubleValue();
}
return sum;
}
Type Erasure
A key thing to understand about generics in Java is type erasure.
After the compiler checks your code for type-safety,
it erases the generic type information. In the compiled
bytecode, your Pair<String, Image> is just a Pair,
and the fields are just Objects.
This was done for backward compatibility with pre-generics Java.
Erasure Example
Because of type erasure, you can’t do certain things. For example, you can’t check the specific generic type at runtime:
Pair<String, String> pair = new Pair<>("a", "b");
// This will produce a compile-time warning!
if (pair instanceof Pair<String, String>) {
// ...
}
// You can only check the raw type
if (pair instanceof Pair) { // This is allowed
// ...
}
Type Erasure II
You also can’t create new instances of a generic type parameter, like new T().
Type Safety
Type Safety
In a statically typed language like Java, we can significantly reduce the number of bugs in our code by leveraging types to model the problems we are solving.
The more accurately we model our problem, the fewer invalid states that are even compilable.
Example
Let’s consider a method that processes a learner based on their current class:
public boolean doSomething(int userId, String studentClass){
//...
}
Example II
For this example, only four values really make
sense, conceptually, but the String type permits
a significantly larger set of values.
Almost every possible input will be invalid!
With sufficient unit tests, we might be able to make it safe…
Stringly Typed
When a String is used to represent data that has a more specific,
constrained set of values, it’s often referred to as being
“stringly typed”.
This is generally considered an anti-pattern because it defers type-checking to runtime, requires extensive validation, and reduces readability.
Enums
As an alternative, we could simply create a four-valued type which exactly matches the valid states in our model.
public enum StudentClass {
FRESHMAN,
SOPHOMORE,
JUNIOR,
SENIOR
}
Enums II
With this type, we can use
public boolean doSomething(int userId, StudentClass studentClass){
//...
}
Now, we don’t need to test for invalid classes. Actually, we can’t even write such tests, because the invalid code won’t compile!
(ignoring null values…)
Enums III
By using a well modeled, constrained type, we can also do other things more easily. Imagine such code:
if(studentClass.equals(FRESHMAN)){
return freshmanStuff;
}else if(studentClass.equals(JUNIOR){
return juniorStuff;
}else{
return seniorStuff;
}
We accidentally forget the Sophomores, who now get processed as Seniors!
Enums IV
Using modern Java features, we could instead write:
return switch(studentClass){
case FRESHMAN -> freshmanStuff;
case JUNIOR -> juniorStuff;
case SENIOR -> seniorStuff;
}
At compile time, this will fail, because we have not
exhaustively covered all cases! This will force us
to either add logic for Sophomores or to add a default
case (which you should generally avoid!).
Enums V
This also protects us in the future! Imagine if
we get a feature request to add support for GRAD
students. We can add this to the enum, and the compiler
will tell us all locations in the code that must be
updated to support this new value in the type!
Testing
There is even support for testing such types in unit tests:
@ParameterizedTest
@EnumSource(StudentClass.class)
void someTest(StudentClass studentClass){
// ... Set up test data ...
final var result = doSomething(id, studentClass);
// ... Test result ...
}
Testing II
If we add an enum value, and have parameterized the unit tests for all code using the enum, then all of our tests will automatically start covering the new value!
Wrappers
Even if some large, primitive type accurately models some data, it’s still probably a good idea to partition the values in your code so you don’t use them in the wrong place.
For instance, instead of passing in an int, we could
define:
public class UserId{
private final int id;
// ...
}
Wrappers II
So, now, we don’t have to worry about passing in an int that does not represent a user’s id:
public boolean doSomething(UserId id, StudentClass studentClass){
// ...
}
Ada Subtypes
Some languages, like Ada, allow you to create new types from existing ones that share representation but are incompatible.
type Celsius is new Float;
type Fahrenheit is new Float;
Ada Subtypes II
Now, you cannot accidentally assign a Celsius
value to a variable expecting Fahrenheit, even
though they are both just floats at runtime!
This is much nicer than Java, because you don’t have to unwrap values to access the underlying primitives.
Warning
Many languages offer type “aliases” which allow you to use an alternative name for a type, but they do not create a new type and can be used interchangebly with the original type!
Limitations
There are some obvious limitations, though:
-
At some point we have raw input that could be invalid, but we only have to validate once at the edge of our code.
-
Java doesn’t care if you just sprinkle null values around, so many of the protections assume you have not done so irresponsibly.
Example III
Often, people will implement an expression structure using such nodes:
public class Expression{
private int value;
private Operation op;
private Expression left;
private Expression right;
}
This requires a lot of safety checks, etc. to make sure that the code is used correctly.
Better Expressions
public interface Expression {}
public class Constant implements Expression {
private final int value;
// ...
}
public class BinOp implements Expression {
private Operation op;
private final Expression left;
private final Expression right;
// ...
}
Better Expressions II
Now, we don’t need to check if there are children or a value, etc. This is encoded in the type itself.
We can also leverage the types to process the tree:
int compute(Expression e){
return switch(e){
case Constant c -> c.value();
case BinOp bo -> doOp(
compute(bo.left()),
compute(bo.right()),
bo.op);
default -> throw new IllegalArgumentException("Unknown Type");
}
}
Exhaustiveness
Because Expression is a standard interface, the compiler
cannot guarantee that Constant and BinOp are the
only implementations.
Therefore, the switch is considered not exhaustive,
and we are forced to handle the default case (or potential
unknown types) at runtime.
Sealed Interfaces
We can fix this by sealing the interface:
public sealed interface Expression
permits Constant, BinOp {}
Now the compiler knows the hierarchy is closed. It can
prove exhaustiveness at compile time, meaning we can
safely remove the default case!
Better Expressions III
public int doOp(int left, int right, Operations op){
return switch(op){
case ADD -> left + right;
case MULT -> left * right;
case SUB -> left - right;
}
}
Even Better Expressions
public class Constant implements Expression{
// ...
}
public interface BinOp extends Expression{}
public class Mult implements BinOp {
// ...
}
public class Add implements BinOp {
// ...
}
// ...
Even Better Expressions II
switch(e){
case Constant c -> c.value();
case Add a -> compute(a.left())+compute(a.right());
case Mult m -> compute(m.left())*compute(m.right());
// ...
}
Even Better Expressions III
switch(e){
case Constant c -> c.value();
case BinOp b -> {
final var left = compute(b.left());
final var right = compute(b.right());
yield switch(b){
case ADD -> left + right;
case MULT -> left * right;
case SUB -> left -right;
// ...
}
}
}
Algebraic Data Types
Algebraic Data Types
Algebraic Data Types, also known as sum types provide a type safe way to concisely model problems.
Sum Types
The term “sum type” comes from the mathematical representation of types. For instance, if we have a type that can be either a 2d or 3d point, we could represent this as:
\[(\mathbb{Z} \times \mathbb{Z}) + (\mathbb{Z} \times \mathbb{Z} \times \mathbb{Z})\]Where we can think of $\times$ as “and” and “+” as “or”.
Sum Types II
In other words, the type we are defining is either a structure with an int and an int or an int and an int and an int.
A tuple being a “product type” and the overall point type being a sum of products.
Java
Bringing this from the theoretical world to the real world, we could imagine that such sum types might be implemented using an interface and different implementations.
Optional
For instance, we could implement an Optional type
from scratch without algebraic data types with:
public class Optional<T> {
final T value;
public Optional(T value){
this.value = value;
}
public T get(){
// what if there is no value...
}
}
Optional II
But since this class represents two clear cases (or products) we could make this a bit safer by implementing this as a sum type:
public sealed interface Optional<T> permits Some, None {}
Optional III
public final class Some<T> implements Optional<T>{
final T value;
public Some(T value){
this.value = value;
}
public T get(){
return value;
}
}
Optional IV
public final class None<T> implements Optional<T>{
}
public static <U> Optional<U> of(U value){
return new Some<>(value);
}
Bloat
This approach works, but these classes really only exist to store data and encode some semantics in the types.
Java requires a lot of boilerplate to accomplish this relatively simple task.
Records
To facilitate such simple classes, a new entity was introduced to the Java programming language: records.
Records allow for very concise definitions of types which primarily just carry data.
Records II
public sealed interface Optional<T> {
record Some<T>(T value) implements Optional<T>{}
record None<T>() implements Optional<T>{}
}
final var o = new Optional.Some<>("hello");
final var s = o.value(); // just use field name
Records III
And other things can be added as well:
public sealed interface Optional<T> {
record Some<T>(T value) implements Optional<T>{}
record None<T>() implements Optional<T>{}
static <U> Optional<U> of(U value) {
return new Some<>(value);
}
}
Points Again
public sealed interface Point {
record Point2D(int x, int y) implements Point {}
record Point3D(int x, int y, int z) implements Point {}
}
Students
public sealed interface Student {
UserId id(); // since it's shared!
record Freshman(UserId id) implements Student {}
record Sophomore(UserId id) implements Student {}
record Junior(UserId id) implements Student {}
record Senior(UserId id) implements Student {}
}
Constructors
By default, the “constructor” is implicitly defined as the list of fields given in the record which binds the values to fields/getters of the same name.
Constructors II
But we can have custom constructors as well:
record Some<T>(T value) implements Optional<T>{
public Some(T value){
this.value = Objects.requireNonNull(value);
}
}
Constructors III
For validation, records offer a concise
“compact constructor” syntax. The parameter
list is omitted, and this.field = field
assignments are implicit.
record Some<T>(T value) implements Optional<T>{
// Compact constructor for validation
public Some {
Objects.requireNonNull(value);
}
}
Switch
Since the ADT pattern uses sealed interfaces,
we can use switch expressions to process them
in an elegant way:
public static Point2D project(Point point){
return switch(point){
case Point2D p -> p;
case Point3D p -> new Point2D(p.x(), p.y());
};
}
Pattern Matching
Even better, by using records, we can extract fields using pattern matching:
public static Point2D project(Point point){
return switch(point){
case Point2D p -> p;
case Point3D(var x, var y, var z) -> new Point2D(x, y);
};
}
This will pull out the nested fields for you and bind them to variables.
Expression ADT
public sealed interface Exp{
record Const(int value) implements Exp{}
record Mult(Exp left, Exp right) implements Exp{}
record Div(Exp left, Exp right) implements Exp{}
record Add(Exp left, Exp right) implements Exp{}
record Sub(Exp left, Exp right) implements Exp{}
}
Expression ADT II
public static int eval(Exp expression){
return switch(expression){
case Const(var i) -> i;
case Mult(var l, var r) -> eval(l) * eval(r);
case Div(var l, var r) -> eval(l) / eval(r);
case Add(var l, var r) -> eval(l) + eval(r);
case Sub(var l, var r) -> eval(l) - eval(r);
}
}
When
While we’re on the topic of switches, we can also add conditional checks to a case to further refine it:
public static int eval(Exp expression){
return switch(expression){
//...
case Div(var l, var r) when eval(r) > 0
-> eval(l) / eval(r);
//...
}
}
Review: Object Oriented Programming
Let’s Review
For this course, being comfortable with object oriented programming concepts and having a good understand of why they are beneficial is required.
Interfaces
Let’s start with interfaces!
First, what are interfaces?
Interfaces II
We could say that interfaces are “contracts” between the implementers of some code and the users of that code.
Interfaces III
In other words, in an interface, you are stating what methods you guarantee will be provided by any class implementing that interface.
Interfaces IV
Next, how do interfaces differ from classes?
Interfaces V
The old school explanation would be that interfaces can not contain implementations of methods. They may only contain method signatures.
(This isn’t actually true anymore, though)
Example
public interface Transform {
String apply(final String input);
}
Interfaces VI
This interface represents the abstract concept of code which performs String transformations.
Note that this code does not do anything! It just states that any class implementing this interface will provide a method called apply that will perform a String transformation.
Classes
Now how about classes?
We mentioned above that classes contain actual implementation details. In other words, they contain code that actually does stuff.
Example II
public class Reverse {
public String transform(final String input){
final StringBuilder sb = new StringBuilder();
for(int i=input.length-1; i>=0; i--){
sb.append(input.charAt(i));
}
return sb.toString();
}
}
Classes II
Is this a class?
Does it perform a String transformation?
Does it implement the Transform interface?
Example III
public class Reverse implements Transform {
public String apply(final String input){
// ...
}
}
Now we have stated that we are agreeing to the “contract” defined by Transform
Example IV
final Reverse transformer = new Reverse();
System.out.println(transformer.apply("Hello");
final Transform transformer = new Reverse();
System.out.println(transformer.apply("Hello"));
What’s the difference here? Why would we do this?
Polymorphism
At this point, there is no real reason to use interfaces at all. What happens, though, when we decide to add another type of transformation to our code.
Example V
if(doReverse){
final Reverse reverse = new Reverse();
return reverse.apply("Hello");
}else if(doNoVowels){
final NoVowels noVowels = new NoVowels();
return noVowels.apply("Hello");
}else if ...
Polymorphism II
While all of these classes do different things, they all, at a high level, are transforming Strings.
So, if we use the Transform interface for all of them, then we can unify them with one variable.
Example VI
final Transform transform;
if(doReverse){
transform = new Reverse();
}else if(doNoVowels){
transform = new NoVowels();
}else if ...
return transform.apply("Hello");
Polymorphism III
This may not seem to impressive, but what if the logic choosing the transformation is not in our code?
What if we have to pass a transform into someone elses code?
What if we need a collection of transformations?
Example VII
final SomeoneElses code = new SomeoneElsesCode();
// We have no idea what this could possibly return!
final Transform transform = code.getTransform();
// ...but we can use it anyway, because we know its interface!
return transform.apply("Hello");
Example VIII
In someone else’s code:
public void setTransform(final Transform t){
transform = t;
}
In our code:
//They have no idea what this is
final Transformer tx = new Reverse();
//...but they can still use it!
code.setTransform(tx);
Example IX
final List<Transform> txs = new ArrayList<>();
txs.add(new Reverse());
txs.add(new NoVowels());
//...
Side Quest
What are all of the angle brackets?
final List<Transform> txs = new ArrayList<>();
Side Quest II
I guess we’re going to need to talk about generics.
We mentioned how an interface can be used to represent different classes by referring to them as instances of the interface instead.
Side Quest III
We can also do this with an ancestor classes, if all of the classes have a common ancestor. So, in the bad old days, a List would simply store Objects, because Object is a common ancestor for all other classes.
Raw Types
This led to problems:
final List txs = new ArrayList();
txs.add(new Reverse());
// Not an error, because it's an object
txs.add("Hello");
// Have to cast, because we need a Transform, not an Object
final Transform tx = (Transform)txs.get(1);
Generics
To fix this, generics were introduced to allow for more type safe code to be written:
final List<Transform> txs = new ArrayList<>();
txs.add(new Reverse());
//Now this is an error
txs.add("Hello");
//And a cast wouldn't be needed if the above didn't crash!
final Transform tx = txs.get(0);
Example X
Let’s improve our Transform interface now:
public interface Transform<T,U> {
U apply(final T input);
}
Now we’re not limited to String transformations!
Example XI
public class Reverse implements Transform<String,String> {
public String apply(final String input){
//...
}
}
Example XII
final List<Transform<String,String>> stringTransformers;
final List<Transform<Integer,Integer>> intTransformers;
final List<Transform<String,Integer>> stringToIntTransformers;
Can you feel the power??? Programming is so awesome.
Inheritance
Ok, let’s dial things back a bit and get back to some basics.
What is inheritance? How does it work?
Inheritance II
Previously, we implemented an interface.
Sometimes, though, we want to extend a class.
Inheritance III
When a class B extends a class A, then the class B will inherit the methods and fields of class A.
Example XIII
public class ReReverse extends Reverse {
}
Example XIV
What will the following do? Will it compile?
final Reverse r1 = new ReReverse();
System.out.println(r1.apply("hello");
Example XIV
public class ReReverse extends Reverse {
public String apply(final String input){
final String reversed = super.apply(input);
final String reReversed = super.apply(reveresed);
return reversed;
}
}
Super?
Example XV
What will the following do?
final Reverse r1 = new ReReverse();
System.out.println(r1.apply("hello");
final ReReverse r2 = new Reverse();
System.out.println(r2.apply("hello");
final Transform t = new ReReverse();
System.out.println("hello");
Polymorphism IV
When we declare a variable’s type, that tells us what fields and methods must exist, but it might not be the precise type of the value bound to that variable.
(The actual value may have more fields and methods!)
Polymorphism V
When we call a method declared in the parent class, the JVM will determine, at run time, what the actual type of the value is, and will use this information to select the correct implementation of the called method.
What is the correct implementation?
Polymorphism VI
If the child class has not overridden the method, then the parent class will be checked for an implementation.
If the child class has overriden the method, then the implementation in the child class is chosen.
Remember, though, that you can have several levels of inheritance!
Access Modifiers
Don’t forget that access modifiers affect what fields and methods are visible to children!
If, for example, a parent class declares a private field, the child can not access it!
Access Modifiers II
| none | private | protected | public | |
|---|---|---|---|---|
| class | Y | Y | Y | Y |
| package | Y | N | Y | Y |
| subclass | N | N | Y | Y |
| world | N | N | N | Y |
Spooky!
A common mistake students (and professionals!) make is to assume that the access modifiers apply to instances of a class. This is not true!
For instance, a private field in class A is visible ot every instance of A!
Example XVI
For example, this code is perfectly valid!
public class A {
private final int x;
//...
public void compareXs(final A anotherA){
// works even though x is private!
return x==anotherA.x;
}
}
Abstract Classes
Let’s circle back around to some of the basics:
An interface (sort of) only provides method signatures.
A class must be completely implemented.
An abstract class is when you want something in between.
Example XVII
public abstract class Censor
implements Transform<String,String> {
public abstract List<String> getBadWords();
public String apply(String input){
for(final String word : badWords){
input = input.replace(word, "!!!")
}
return input;
}
}
Now we can create different variations by subclassing and implementing getBadWords.
Inheritance IV
What if we want to inherit from two classes?
Inheritance V
You can’t!
You can implement several interfaces, but you can only extend one class (concrete or abstract).
However…
Default Methods
You can now, actually, provide “default” implementations of methods in interfaces.
Which means that you can often accomplish what you were trying to do with two parent classes by instead implementing two interfaces with default methods.
Default Methods II
There are, however, limitations. First, remember that you can only store static, constant fields in an interface. If you need instance data for your default methods, you are out of luck.
Default Methods III
You can, though, add a getter to the interface for the instance data, and use that in your default method.
Then implementers will declare their own instance fields and implements the getter.
Example XVII
public interface Censor extends Transform<String,String> {
List<String> getBadWords();
default String apply(String input){
for(final String bad : getBadWords()){
input = input.replace(bad, "!!!");
}
return input;
}
}
Implement or Extend
Another common mistake is to try and implement an interface in another interface. This makes no sense, because you aren’t (generally) providing an implementation!
So, interfaces extend other interfaces!
Multiple Interfaces
An interesting use for multiple interfaces is to create an interface for each kind of behavior that might be needed, and mixing them together.
Example XVIII
public interface Labeled {
public String getLabel();
}
public interface Logged {
public List<String> getLog();
}
Example XVIV
public class Reverse
implements Transform<String,String>, Labeled, Logged {
private final List<String> log = new ArrayList<>();
public String getLabel(){return "Reverse (Transform)";}
public List<String> getLog(){return log;}
public String apply(final input){
log.add("Starting transform of input: " + input);
//...
log.add("Transform complete:" + result);
return result;
}
}
Multiple Interfaces II
So, in addition to being able to use this class wherever we need a Transform, we can use it anywhere we expect, for example, instances with a label.
Multiple Interfaces III
For example, imagine a UI where we can select operations to perform. Some might be transformers, other might not be, but we can put them all in a common UI widget with a nicely displayed label if they all implement the Labeled interface!
instanceof
At runtime, though, we may not know what interfaces are implemented, so we will need to check using the instanceof operator.
Example XIX
public void doTransform(final Transform<String,String> t){
final String input = getInput();
final String output = t.apply(input);
if(t instanceof Logged){
final Logged logged = (Logged) t;
printLog(logged.getLog());
}
writeOutput(output);
}
Appendix: Lambda Expressions
Lambda Expressions
In this appendix, we will discuss interfaces, anonymous classes, and lambda expressions which are becoming a more commonly used feature in Java (and other languages) and allow for writing incredibly succinct, clear code.
Interfaces, Again
In order to understand lambda expressions, we will start with interfaces and slowly work our way to proper lambda expressions.
An Interface
Let’s use the Transform interface from our Object Oriented review:
public interface Transform {
String apply(final input String);
}
Implementations
We can use this interface to implement types of Transformers.
public class ToCaps implements Transform {
public String apply(final String input){
return input.toUpperCase();
}
}
Instances
Once we have a concrete class defined, we would typically create and use instances as follows:
final Transform tx = new ToCaps();
final String result = tx.apply("hello");
return result;
Anonymous Classes
Sometimes, though, we will only be creating instances for a class in one location in our code. Creating another file and another class is overkill, so instead we could use an anonymous class.
Anonymous Classes II
final Transform tx = new Transform(){
public String apply(final String input){
return input.toUpperCase();
}
};
final String result = tx.apply("hello");
return result;
Anonymous Classes III
Basically, this allows us to declare the same class inline.
It’s “anonymous,” because it no longer has a name.
(it doesn’t need one, because we are only referencing this class here!)
Going Further
If you look at the declaration of the anonymous class, you see that we have declared the variable to be a Transform, so in theory, we shouldn’t have to tell the compiler we are creating a Transform.
Going Further II
This won’t actually compile, but you should be able to see how the compiler could be implemented so that it would.
final Transform tx = {
public String apply(final String input){
return input.toUpperCase();
}
};
final String result = tx.apply("hello");
return result;
Going Further III
Also, since there is only one method in the Transform interface, it seems like we should also be able to leave the method name, parameter type, return type, and access modifier out.
final Transform tx = {
(input){
return input.toUpperCase();
}
};
final String result = tx.apply("hello");
return result;
Lambda Expression
Now, if we just eliminate unnecessary braces and tweak the syntax a bit, we can arrive at the following, which will compile.
final Transform tx = (input)->{
return input.toUpperCase();
};
final String result = tx.apply("hello");
return result;
Lambda Expression II
In this particular case, since there is only a single statement in the method body, we can be even more concise.
final Transform tx = (input)->input.toUpperCase();
final String result = tx.apply("hello");
return result;
Lambda Expressions III
And since there is only a single parameter, we can do a little better.
final Transform tx = input->input.toUpperCase();
final String result = tx.apply("hello");
return result;
Lambda Expressions IV
This may not seem that interesting, but let’s look at a more complex example:
public class Transformer {
private final Transform transform;
public Transformer(final Transform tx){
this.transform = tx;
}
public List<String> transform(final Source source){
final List<String> output = new ArrayList<>();
for(final String input : source){
output.add(transform.apply(input));
}
return output;
}
}
Lambda Expressions V
Now we can write really succinct code like:
private final Source = getSource();
final Transformer toUpper =
new Transformer(s->s.toUpperCase());
toUpper.transform(source);
final Transformer toLower =
new Transformer(s->s.toLowerCase());
toLower.transform(source);
GUI
…or maybe you have experienced the pain of writing a bunch of ActionListeners?
button.addActionListener(
event->JOptionPane.showMessageDialog(this, "I was clicked!")
);
Even Better
In addition to lambda expressions we can also use method references to avoid even more boiler plate code!
Even Better II
Which gives us:
final Transformer toUpper =
new Transformer(String::toUpperCase);
Instead of
final Transformer toUpper =
new Transformer(s -> s.toUpperCase());
Functions
The most generalized version of this code would not even specify that a Transform is needed. Instead, the constructor would be:
public Transformer(Function<String,String> f){
//...
}
Java provides Function and BiFunction interfaces to represent any one argument or two argument method, class, etc.
Also
For zero argument functions, Java provides the Supplier interface:
final Supplier<String> s = ()->"Hello!";
And for a “function” with no return, the Consumer interface:
final Consumer<String> c = s->System.out.println(s);
And Finally
If you want to pass a computation that has no parameters and no output, then you can use the Runnable interface:
new Thread(
()->{
while(true){
System.out.println("JavaScript Sucks");
}
}
).start();
Closures
One other interesting thing you can do with anonymous classes and lambda expressions is use them to capture variables in their closures.
Closures II
public Transformer create(String message, int count){
return new Transformer(input->{
final StringBuilder sb = new StringBuilder();
for(int i=0; i<count; i++){
sb.append(text);
}
});
}
final Transformer t = create("hi",4);
t.transform(source); //message and count are out of scope!?
Closures III
This works, because any variable referenced in the lambda expression is captured and will be accessible for the life of the expression!
Appendix: Don't Null
Billion-Dollar Mistake
I call it my billion-dollar mistake. It was the invention of the null reference in 1965. […] I couldn’t resist the temptation to put in a null reference, simply because it was so easy to implement.
Billion-Dollar Mistake II
In reality, 1 billion dollars is a huge understatement of the financial damage caused by null references.
Most developers spend a comically large amount of time chasing null pointers.
Billion-Dollar Mistake III
…but you don’t have to!
This one secret will save you time and money–more than the cost of this course!
What’s The Problem?
Many will tell you that null pointers aren’t a problem if you’re a good programmer.
final User user = getUser(10);
final String name;
if(user !=null){
name = user.getName();
}else{
name = "Not Found";
}
The Problems
Problem: Every method could, possibly, return a null value, so to be safe you need to check the result of every method.
The “good programmers” don’t do this, though. They “know” which methods need to be tested…which is why they, too, get null pointer exceptions.
The Problems II
Problem: If you don’t want to test every method, you need to read the documentation for methods to determine which ones can return null.
The “good programmers” don’t do this either…which is why they, too, get null pointer exceptions.
The Problems III
Problem: If you do read the documentation, it is imperative that the documentation is correct and complete.
The “good programmers” don’t write and update documentation sufficiently, though…which is why they, too, get null pointer exceptions.
The Good Programmers
Of course, the “good programmers” always have excuses for why their null pointer problems are not their fault and continue to have null pointer problems.
The Dumb Programmer
Meanwhile, the “incompetent” programmer acknowledges his or her inability to cope with complex systems and asks the compiler for help.
public Optional<User> getUser(int id){
if(userExists(id)){
return Optional.of(new User(id));
}else{
return Optional.empty();
}
}
The Dumb Programmer II
Now, this won’t even compile!
final User user = getUser();
The compiler complains, because the return value is not a User. But we need an User…
The Dumb Programmer III
final Optional<User> maybeUser = getUser(10);
final String name;
if(maybeUser.isPresent()){
name = maybeUser.get().getName();
}else{
name = "Not Found";
}
Did we just do the same thing as the good programmer?
The Difference
Sort of. There is one immediate difference, though: Now we are forced by the compiler to address the possibility of no value being returned.
This is already a big gain with only slightly more code needed than the good programmer’s approach.
The Difference II
If your team is on board with never returning null values (which is significantly easier than avoiding null values returned from methods unexpectedly), then you can use Optional values to eliminate null pointer exceptions from your code.
Java Is Not Great
Java, unfortunately, does not prevent you from returning a null value even if the return type is an Optional value.
You should have used Haskell.
Bonus
Another bonus to this approach is that the return type itself documents the fact that the method may not return a value. Even better, if this documentation changes, the compiler will force you to rethink your use of the method!
What About Get()
Of course, you could just assume that the method returns a value and write:
final String name = getUser(10).get().getName();
Which isn’t any better than
final String name = getUser(10).getName()
Using the old code.
Psychology
The big difference, though, is psychology. If you know the meaning of an Optional return type, and you decide that, even though this method is guaranteed to sometimes not return a value, you are going to roll the dice, then there is literally no programming language feature that can help you, because you willfully do bad things.
Psychology II
On the other hand, the developer who doesn’t check for a null is often just being careless. There is no red flag being waived in his or her face about the certain danger.
So, Optional return types flip the responsibility around.
Psychology III
With null values, you have to be responsible enough to make sure you don’t screw up.
With Optional values, you are almost forced to write good, safe code and have to male a conscious decision to do the bad thing.
(Some even argue that get() should not exist in the Optional class)
The Problems IV
Problem: Why are we returning a default value of “Not Found”? If the User does not exist,
then why should the name exist? We could just return a null, but that’s bad!
Instead, we should just return an Optional name!
A Mess
final Optional<User> maybeUser = getUser(10);
if(maybeUser.isPresent()){
final User u = maybeUser.get();
return Optional.of(u.getName());
}else{
return Optional.empty();
}
Am I Trolling?
At this point you should be ready to revolt and assume I am trolling you.
Are you really, supposed to litter Optional wrappers throughout every line of code?
Improvement
No! Higher order functions will rescue us and make life beautiful.
The Optional class defines a method called map which accepts a function as its argument.
Improvement II
More specifically, for the type Optional of type T, it accepts a function that takes an object of type T and returns some other type of object.
Improvement III
Using this, we can write the following instead:
return getUser(10).map(u->u.getName());
If the Optional contains a value, the function is applied to it, resulting in an Optional containing an String. Otherwise, the whole thing is just an empty Optional.
The Dumb Programmer Wins
Now, we have obtained safety and simpler code. Good programmers and their null checks have been thoroughly defeated at this point.
Going Further
What if the getName() method itself returns an *Optional
final Optional<String> result =
getUser(10).map(u->u.getName());
This doesn’t compile. Why?
Improvement IV
The Optional type also provides a method flatMap that takes a function which returns an Optional value and “flattens” the Optional layers so that there are no nested Optionals
Awesome
Now, we can write safe code in the face of missing values quite simply:
return getUser(10)
.flatMap(u -> u.getName())
.map(n -> n.toUpperCase())
.filter(n -> n.equals("PHILLIP"))
.map(n->"User: " + n)
Improvement V
We can do a little cleanup using method references
return getUser(10)
.flatMap(User::getName)
.map(String::toUpperCase)
.filter(n -> n.equals("PHILLIP"))
.map(n->"User: " + n)